
导读:有没有想过这个问题:当我们执行
git add xxx和git commit -m 'xxx'的时候,Git都做了点什么?
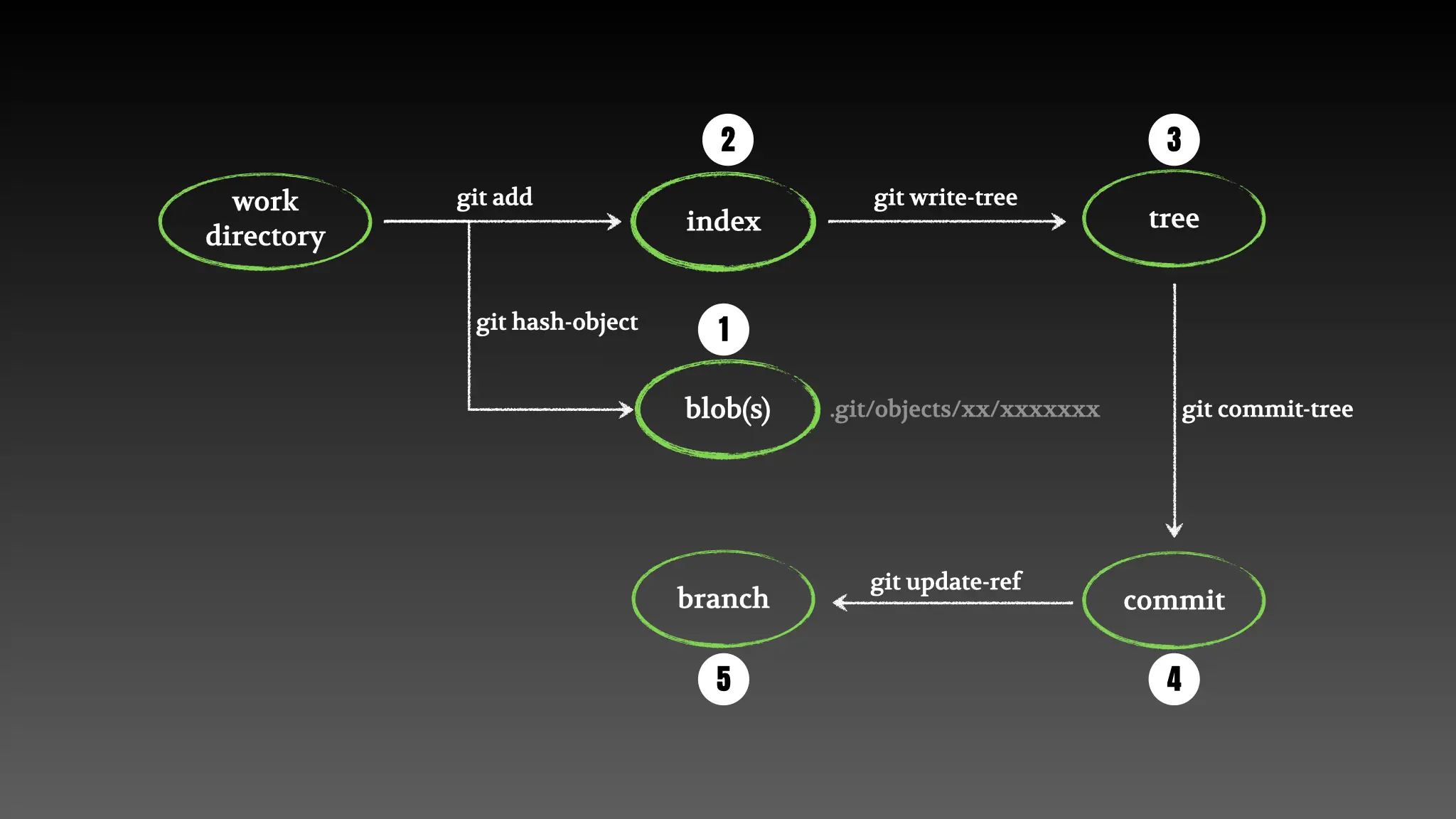
上面是一张简单的代码入库流程图:
用户执行git add xxx的动作分解:
.git/objects/xx/,这里的xx为SHA1值的第1个字节对应的HEX值,注意这里创建的blob对象中存储的是源文件使用zlib压缩后的内容,并不是原始内容直接存储,这样大大降低了磁盘空间占用。.git/index。用户执行git commit -m 'xxx'的动作分解:
.git/objects/xx/目录下,这里在存储之前,同样会计算tree对象的SHA1值,然后进行分目录存放。.git/objects/xx/目录下。.git/refs/heads/master。那么问题来了,如果两个文件的内容一样,那么在git中是保留一份还是两份呢?
按照步骤1中的描述我们可以得知,应该是只保留一份数据,因为文件的内容相同,SHA1值就相同,对应Git库中的BLOB对象文件名就相同,因此只能是一份记录。但这里需要注意的是,虽然文件内容相同,但文件名不同或者位于不同的目录中,因此,对应的是不同的tree对象条目。
【文章不错,鼓励一下】
